파트 1(https://seanshkim.tistory.com/104)에선 내가 족적 검색 시스템 연구를 하게 된 배경과
처음에는 어떤 논문을 구현하려고 했는지, 그리고 그게 왜 실패로 끝났는지 자초지종을 설명했다.
이번 글에선 내가 그 다음 단계로 수행한 과정을 설명하려고 한다.
키워드
- 이미지 검색 시스템, 또는 image retrieval task
- Label
- FID-300
- 자기 지도 학습(Self-Supervised Learning, Unsupervised Learning)
- MSN(Masked Siamese Network)
- ImageNet
- Pretrained Model
족적 검색 시스템에서 '정답' 이미지란?
이미지 검색 시스템에서 정답(label) 데이터는 어떻게 정의할 수 있을까?

딥러닝의 이미지 분류 task에서 정답(label)은 텍스트 또는 카테고리를 의미하는 숫자로('container ship'=0, 'leopard'=1, mushroom=2...)로 정의된다면,
이미지 검색 시스템에서 정답은 입력 이미지와 패턴이 일치하는(또는 유사한) DB 내 이미지로 정의할 수 있다.
따라서 족적 검색 시스템 AI를 만들기 위해 지도 학습(supervised learning)을 시도한다면,
현장 이미지와 일치하는 신발 이미지를 데이터베이스에 충분히 확보해 놓아야 한다.
다시 말해서 나이키나 아디다스같은 운동화부터 시작해서 구두, 부츠, 크록스, 슬리퍼 등 온갖 종류의 신발 모델 이미지를 최대한 많이 보유하고 있어야 지도 학습 방식으로 검색 시스템을 개발하기 쉬울 것이다.
하지만 내게는 그런 데이터베이스가 없다는 게 문제였다.
떠올린 해결책: 딥러닝 모델이 '스스로 알아서' 신발 패턴을 학습하게 하자
그래서 내가 떠올린 해결책은 자기 지도 학습, 즉 SSL(Self-supervised learning)이었다.
주어진 정답 없이 기계학습 모델이 데이터의 패턴을 알아서 학습하는 패러다임을 말한다.
왜 하필 자기 지도 학습 방식을 시도했을까?
일반적으로 이미지 검색 시스템을 구축한다고 하면 Siamese Network 기반의 모델을 만들거나
contrastive learning(triplet loss, contrastive loss) 방식을 대부분 적용한다.
물론 내가 나중에 완성한 코드도 샴 네트워크 기반의 모델이었지만, 이미지 task에서 비지도 학습은 그리 보편적인(가장 먼저 선호되는) 단계는 아닌 것 같다. 그렇기 때문에 내가 왜 비지도 학습을 먼저 시도하려고 했는지 그 이유를 설명하려고 한다.
1. 데이터 자체도 부족했지만, 정답(label) 데이터는 더욱 귀했다
내가 연구 인턴을 했을 때 학습에 당장 활용할 수 있는 데이터는 사실상 FID-300 데이터셋이 전부였다.
현장 이미지 300장, 등록 이미지 1,175장으로 매우 작은 데이터셋이다.
하지만 현장 이미지(=입력 데이터)와 일치하는 DB 이미지(=등록 이미지, 비교군) 쌍이 잘 정리되어 있다는 게 장점이다.
FID-300은 입력 데이터에 대한 정답이 존재하기 때문에 지도 학습 방식으로 딥러닝 모델을 학습할 수 있다.
반면에 인턴 기간 후반부에 경찰청에서 직접 제공받은 데이터셋은 상황이 조금 달랐다.
이 데이터셋은 수량이 FID-300보다 훨씬 많았지만, 아직 annotation이 되어 있지 않아 지도 학습에 제대로 활용하기 어려웠다.
그래서 자기 지도 학습을 떠올린 이유다.
지도 학습은 반드시 annotation이 있는 데이터셋을 필요로 하는 반면 자기 지도 학습은 데이터에 annotation이 없어도 학습에 사용할 수 있기 때문이다.
2. 과연 자기 지도 학습은 데이터의 도메인을 가리지 않고 좋은 성능을 발휘할까?
두 번째 이유는 순전히 내 호기심 때문이었다.
내가 쓸 수 있는 데이터셋이 크게 다섯 가지인데 이 데이터셋마다 이미지 형식이나 색상, 수집된 방식이 모두 달랐다.
한마디로 '데이터의 도메인(=특성, 수집된 방식, 환경 등)'의 차이가 있었다.
<활용 가능 족적 데이터셋 종류>
- FID-300
- WVU(West Virginia University) 2019
- ISU(Iowa State University) Dataset
- Walmart Shoe Database
- 경찰청 자체 보유 족적 데이터
자기 지도 학습 방식으로 모델을 학습한다면, 이미지의 형식을 맞출 필요도 없이 신발 밑창의 패턴 특성(feature)을 학습하는 것에 초점을 맞추면 된다.
그렇다면 데이터의 도메인이 달라도 모델이 신발 이미지를 효과적으로 학습할 수 있지 않을까? 가 내 의문이었다.
그래서 이 데이터셋들을 모두 하나로 합쳐서 학습에 돌리고, 또 각 데이터셋의 조합을 다르게 해서 어느 조합일 경우에 가장 성능이 좋은지 실험을 해보는 게 원래 계획이었다.
(하지만 결국 내 원대한 계획은 시간 부족으로 마무리를 짓지 못했다... 🥲)
자기 지도 학습 모델 선정을 위한 논문 서칭
연구 방향의 대략적인 아이디어를 떠올렸다면, 다음 단계는 어떤 모델을 적용할 것인가?이다.
바로 깃허브나 허깅 페이스같은 오픈소스 커뮤니티를 찾아볼 수도 있었겠지만 헛걸음질을 더 이상 하지 않기 위해 우선 논문을 찬찬히 살펴보기로 했다.
내가 자기 지도 학습 테마에 대해 서칭한 논문은 총 5개다.
- [MoCo] Momentum Contrast for Unsupervised Visual Representation Learning (2019.11)
- [SimCLR] A Simple Framework for Contrastive Learning of Visual Representations (2020.02)
- [DINO] Emerging Properties in Self-Supervised Vision Transformers (2021.04)
- [MAE] Masked Autoencoders Are Scalable Vision Learners (2021.11)
- [MSN] Masked Siamese Networks for Label-Efficient Learning (2022.04)
내가 논문을 선택한 기준은 크게 세 가지다.
- 언제 발표되었는가? (최신 논문인가?)
- 믿을 만한가? (저자와 피인용수)
- 오픈소스가 있는가? (구현 현실성)
1. 논문의 발표 시점. 간혹 엄청난 피인용수를 자랑하지만 알고보니 발표한 지 꽤 오래된 논문도 더러 있다.
특히나 AI 분야에서는 1년, 아니 6개월만 지나도 이전 모델의 단점을 개선・보완한 모델이 파죽지세로 나오기 때문에 주의할 필요가 있다.
하지만 YOLOv5처럼 시간이 지나도 여전히 활용성이 높고 이미 성능이 충분히 좋은 모델도 있기 때문에 상황에 따라 신중히 판단해야 할 것 같다.
2. 믿을 만한가? 누가 썼는지, 어느 기관 또는 기업에서 발표했는지, 그리고 피인용수는 얼마나 되는지 확인해야 한다.
예전에 AI 분야 대학원생 사이에서는 중국 학교에서 발표한 논문은 믿고 거르라는 우스개소리가 있었다(농담일 뿐...).
그 이유인즉슨 중국인 저자들이 올린 코드로 구현해보려고 하면 하나같이 에러 투성이고 제대로 구현되는 게 없었다,라는 이유였는데 이제는 사실이 아닌 걸 안다. 하지만 여전히 Google이나 OpenAI, Meta AI Research 같은 빅테크에서 발표하는 논문이 더 신뢰가 가는 건 어쩔 수 없는 것 같다. 그리고 나같은 초심자가 접하게 될 AI 논문은 대부분 피인용수가 말도 안되게 높거나, 대개 빅테크나 유명 대학 출신의 대가들이 쓴 논문일 것이다.
3. 오픈소스가 있는가? 예전에 논문을 한참 읽고 이야, 정말 기가 막히게 잘 만든 모델인 걸 하고 구현하려고 봤더니 막상 소스코드가 없어서 당혹스러웠던 경험이 몇 번 있었다. 그만큼 가장 현실적이면서 가장 중요한 항목이다. 프로젝트를 시작하려는 AI 초심자에게 논문은 아무리 훌륭해도 재구현할 오픈소스 코드가 없다면 없는 거나 마찬가지다. 내가 뒤에서 (조금 결이 다르지만) 왜 이 항목을 유달리 강조하는지 설명하겠다.
위 기준에서 성능은 따로 넣지 않았다. 어차피 딥러닝계에선 '최신 + 빅테크 or 대가의 논문 = SoTA(성능이 제일 뛰어남)'이라는 공식이 99% 성립하기 때문이다.
이 기준을 통해 내가 최종적으로 선택한 논문은 MSN(Masked Siamese Networks)이었다.
자기 지도 학습 방식으로 당시 SoTA 성능을 달성했고, 이미 피인용수가 높은데다(2024.01 기준 160회 이상) Facebook AI Research와 협업한 연구이면서 깃허브와 허깅 페이스에도 공개 모델이 업로드되어 있었다.
그렇게 내 연구 프로젝트는 순조로워보이기만 했다. 후후후...
MSN(Masked Siamese Network): 왜 재구현에 실패했는가?
결론부터 말하면 또 실패했다(또!). 그렇지만 실패에서 배운다고 이번 실패를 통해 깨달은 점이 아주 많다.
먼저 MSN 모델을 활용하기 위해 아래 두 곳을 참고했다.
GitHub - facebookresearch/msn: Masked Siamese Networks for Label-Efficient Learning (https://arxiv.org/abs/2204.07141)
Masked Siamese Networks for Label-Efficient Learning (https://arxiv.org/abs/2204.07141) - GitHub - facebookresearch/msn: Masked Siamese Networks for Label-Efficient Learning (https://arxiv.org/abs/...
github.com
facebook/vit-msn-base · Hugging Face
Vision Transformer (base-sized model) pre-trained with MSN Vision Transformer (ViT) model pre-trained using the MSN method. It was introduced in the paper Masked Siamese Networks for Label-Efficient Learning by Mahmoud Assran, Mathilde Caron, Ishan Misra,
huggingface.co
공개한 pre-trained 모델 가중치가 학습이 안되어 있다니요?
앞서 올린 Facebook Research의 MSN 깃허브 리포지토리를 들어가보면 떡하니 Pre-trained models 가중치를 올려놓았다.
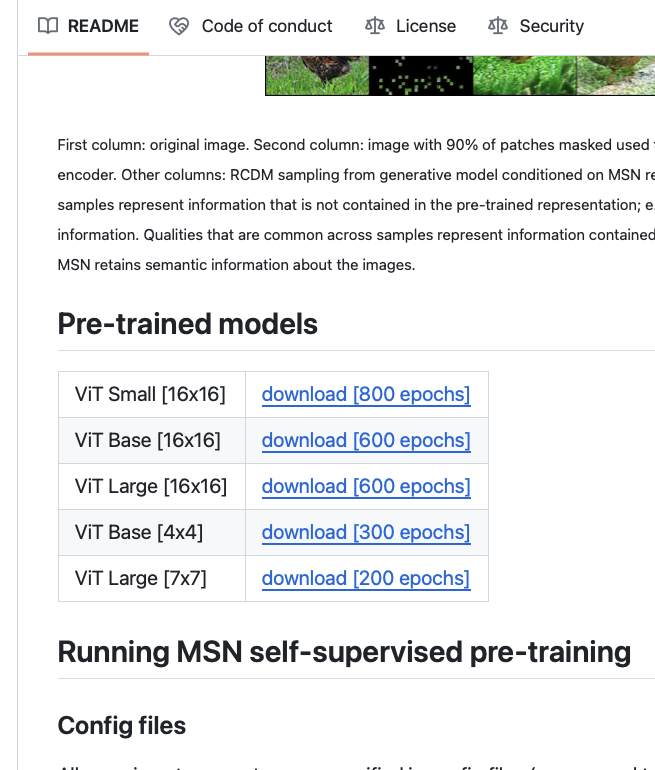
아싸! 속으로 쾌재를 외친 나는 당연히 깃허브에 업로드된 가중치 파일이 모두 MSN 모델에 해당한다고 생각했고,
때문에 ViT Large 600 epochs 가중치를 다운로드받았다.
또 성능을 테스트하기 위해 ImageNet 데이터셋으로 이미지 분류 task(MSN 모델은 ImageNet 데이터셋으로 pre-train시킨다고 논문에 나와있다)로 실험해봤다.
결과는?
14:30:02 - Model: checkpoint/msn_os_logs/vitl16_600ep.pth.tar
14:30:02 - Dataset location: ./imagenet
14:30:02 - Batch size: 64
14:30:02 - Number of workers: 4
14:30:02 - Number of images: 50000
14:32:45 - Total time: 162.66s
14:32:45 - Custom accuracy: 0.10%
정확도가 무려 0.1%이다!
ImageNet1K 카테고리가 1000개임을 감안하면 1000개 중에 1개 꼴로 맞추는 셈이니 그야말로 완벽한 랜덤(완벽하게 학습이 안되어있다)이라고 할 수 있겠다.
믿기지가 않았다. 혹시 Facebook Research에서 깃허브에 잘못된 파일을 올린 건 아닌가?
싶어서 이번엔 Hugging Face API를 이용해서 학습을 시도해봤다. 아래는 Hugging Face로 모델을 불러오는 코드다.
import torch
from transformers import ViTMSNForImageClassification
pretrained_model = 'facebook/vit-msn-base'
model = ViTMSNForImageClassification.from_pretrained(pretrained_model)
자세한 모델 학습 코드는 내용이 너무 길어질까봐 여기에 따로 첨부하지 않았다.
대신 내 깃허브(https://github.com/seanshnkim/msn_shoeprint_retrieval)의 hg_model_eval_torch.py에 있으니 궁금한 분들은 참고하시길 바란다.
그리고 또 다시 결과는 똑같았다.
16:23:50 - Based on Hugging Face Transformer model: facebook/vit-msn-base
16:23:50 - Dataset location: ./imagenet
16:23:50 - Batch size: 64
16:23:50 - Number of workers: 4
16:23:50 - Number of images: 50000
16:26:33 - Total time: 163.59s
16:26:33 - Custom accuracy: 0.10%
정말 납득이 안 갔기 때문에 오기가 생기기 시작했다.
모델 가중치가 잘못된 것인지, 아니면 내가 짠 코드가 잘못된 건지 아직 확신할 수 없었기 때문에
또 하나 검증 단계를 시도해보기로 했다.
만약 내가 작성한 동일한 코드에 모델 가중치만 아예 다른 모델로 바꾸었을 때 성능이 제대로 나온다면,
Facebook이 올린 모델 가중치가 학습이 안 된거라고 결론 내릴 수 있지 않을까?
동일한 코드, 다른 모델 가중치(google/vit-base-patch16-224)로 테스트해보기
사용 모델은 Hugging Face의 google/vit-base-patch16-224로 가장 일반적인 Visual Transformer 모델이라고 할 수 있다.
내가 작성한 코드에 모델 가중치만 다른 파일로 바꿔치기 했더니 나온 결과는 놀랍게도 성공이었다.
15:57:23 - Based on Hugging Face Transformer model: google/vit-base-patch16-224
15:57:23 - Dataset location: ./imagenet
15:57:23 - Batch size: 64
15:57:23 - Number of workers: 4
15:57:23 - Number of images: 50000
16:00:06 - Total time: 163.43s
16:00:06 - Custom accuracy: 75.66%
다시 정리하자면,
- ImageNet1K 데이터셋으로 Facebook Research MSN(Masked Siamese Network) 깃허브 리포지토리에 업로드된 모델을 테스트했더니 정확도가 0.1% 나왔다.
- Hugging Face에서 제공하는 동일 MSN 모델 가중치에 대해서도 0.1%가 나왔다.
- 정확도 테스트하는 내 코드가 이상한 건가 싶어서 코드는 그대로 놔두고 모델 가중치만 구글 ViT로 바꿨더니 성능이 75.6% 나왔다.
따라서 난 결론을 다음과 같이 내렸다.
'현재 공개된 MSN(Masked Siamese Network) 모델 가중치는 어찌된 영문인지는 모르겠지만 전혀 학습이 안 되어있고, 그렇기 때문에 내 연구에도 활용할 수 없다.'
마무리
사실 아직도 내가 무언가를 놓쳤다는 찜찜함이 남아있지만(Facebook 같은 곳이 학습도 안된 모델 가중치를 올렸을 리 없고, 무엇보다 관련 이슈도 전혀 없었기 때문) 소득은 분명히 있었다고 생각한다.
첫째, 시간은 오래 걸렸지만 내가 거쳤던 사고과정과 의문점, 코드를 모두 기록하려고 노력했다.
덕분에 연구 인턴을 마치고 한달이 훌쩍 지난 지금에도 내가 남겨놓은 기록을 찾아보면서 회고록을 자세히 쓸 수 있었다.
둘째로, 다시 한번 AI 프로젝트에서 오픈 소스 기반으로 구현을 빨리 해내는 역량이 얼마나 중요한지 깨달았다.
설마 사용하라고 공개된 가중치가 아예 학습이 안되어있을 줄은 꿈에도 몰랐지만,
그래도 다른 모델로 빨리 넘어가거나 다른 소스 코드를 찾아봤더라면 시간을 절약할 수 있었을 것이다.
1) 믿을 만한 출처의 공개 AI 모델을 찾아
2) 빠른 시간 내에 에러 없이 성능 테스트하고
3) 내 커스텀 데이터로 fine-tuning하기
독창적인 AI 모델을 개발해야 하는 연구자가 아닌 이상, 이미 나와있는 파운데이션 모델을 활용하는 엔지니어라면
이 세 단계를 얼마나 빠르게 수행하는가가 관건이라고 생각한다.
다음에는 내가 연구 인턴에서 마지막으로 수행했던 단계(Siamese Network 적용과 코드 모듈화)에 대해서 논의해보려고 한다.
'회고록 > 포스코 AIㆍBig Data 아카데미' 카테고리의 다른 글
| [Part 1] 용의자의 신발을 찾아라: AI 기반 족적 검색 시스템을 개발하기까지 겪었던 시행착오들 (1) | 2023.12.20 |
|---|---|
| 포스텍 인공지능연구원(PIAI) 23기 인턴 후기 [생활 편] (2) | 2023.12.19 |
| 포스코 청년 AI Big Data 아카데미 23기 후기 11편: AI 최종 발표와 느낀 점 (2) | 2023.12.09 |
| 포스코 청년 AI Big Data 아카데미 23기 후기 10편: AI 교육에 크게 기대해선 안되는 이유 (1) | 2023.12.09 |
| 포스코 청년 AI Big Data 아카데미 23기 후기 9편: 연구 인턴 면접 후기 (0) | 2023.11.12 |




